| Subject | Question No. |
|---|---|
| Reasoning | 1 -50 |
| General Awareness | 51 - 100 |
| Civil - Technical | 101 - 200 |
Quiz-summary
0 of 200 questions completed
Questions:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
Information
Time Limit - 2 Hours

You have already completed the quiz before. Hence you can not start it again.
Quiz is loading...
You must sign in or sign up to start the quiz.
You have to finish following quiz, to start this quiz:
Results
0 of 200 questions answered correctly
Your time:
Time has elapsed
You have reached 0 of 0 points, (0)
| Average score |
|
| Your score |
|
Categories
- Not categorized 0%
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- Answered
- Review
-
Question 1 of 200
1. Question
1 pointsIn each of the questions below are given three statements followed by two conclusions numbered I and II. You have to take the given statements to be true even if they seem to be at variance from commonly known facts. Read all the conclusions and then decide which of the given conclusions logically follows from the given statements disregarding commonly known facts.
Statements : All cards are boxes.
I. No box is slate.
II. Some slates are tiles.
Conclusions
I. No slate is card.
II. Some tiles are boxes.
Correct
Incorrect
According to the statements, the Venn-diagram will be

-
Question 2 of 200
2. Question
1 pointsIn each of the questions below are given three statements followed by two conclusions numbered I and II. You have to take the given statements to be true even if they seem to be at variance from commonly known facts. Read all the conclusions and then decide which of the given conclusions logically follows from the given statements disregarding commonly known facts.
Statements: Some papers are arrows.
All arrows are sticks.
Some sticks are boards.
Conclusions :
I. Some boards are papers.
II. No board is paper.
Correct
Incorrect
According to the statements, Venn-Diagram will be

-
Question 3 of 200
3. Question
1 pointsIn each of the questions below are given three statements followed by two conclusions numbered I and II. You have to take the given statements to be true even if they seem to be at variance from commonly known facts. Read all the conclusions and then decide which of the given conclusions logically follows from the given statements disregarding commonly known facts.
Statements
I.All ropes are tiles.
II. Some tiles are bangles.
III. All bangles are nails.
Conclusions
I. Some nails are ropes.
II. Some nails are tiles.
Correct
Incorrect
According to the statements, the Venn-daigram will be

-
Question 4 of 200
4. Question
1 pointsIn each of the questions below are given four statements followed by four conclusions numbered I, II, III and IV. You have to take the given statements to be true even if they seem to be a
variance from commonly known facts. Read all the conclusions and then decide which of the given conclusions logically follows from the given statements disregarding.commonly known facts.Statements
All rings are phones.
All phones are spoons.
Some phones are files.
All files are covers.
Conclusions
I. Some files are rings.
II. Some covers are spoons.
III. Some spoons are phones.
IV. Some rings are covers.
Correct
Incorrect
According to the statements, the Venn-diagram will be

-
Question 5 of 200
5. Question
1 pointsIn each of the questions below are given four statements followed by four conclusions numbered I, II, III and IV. You have to take the given statements to be true even if they seem to be a
variance from commonly known facts. Read all the conclusions and then decide which of the given conclusions logically follows from the given statements disregarding.commonly known facts.Statements
Some carpets are books.
All books are pens.
Some pens are cartoons.
All cartoons are notebooks.
Conclusions
I. Some cartons are carpets.
IL Some catroons are books.
III. Some pens are carpets.
IV. Some notebooks are pens.
Correct
Incorrect
According to the statements, the Venn-diagram will be

-
Question 6 of 200
6. Question
1 pointsThe following questions consist of two numbers/letters/words each that have a certain relationship with each other, followed by four pair of numbers/ letters/ words. Select the pair which has the same relationship as the original pair of numbers/letters/words.
Mirror : Glass
Correct
Incorrect
As, 'Mirrol is made from 'Glass'. Similarly, 'Shirt' is made from'Cloth'.
-
Question 7 of 200
7. Question
1 pointsThe following questions consist of two numbers/letters/words each that have a certain relationship with each other, followed by four pair of numbers/ letters/ words. Select the pair which has the same relationship as the original pair of numbers/letters/words.
Medicine : Dose
Correct
Incorrect
As, Me&cine' is taken in 'Doge'. Similarly, 'Food' is taken in'Quantity'.
-
Question 8 of 200
8. Question
1 pointsThe following questions consist of two numbers/letters/words each that have a certain relationship with each other, followed by four pair of numbers/ letters/ words. Select the pair which has the same relationship as the original pair of numbers/letters/words.
Mobile : SMS
Correct
Incorrect
A,s, 'Mobile' has 'SMS'. Similarly, 'Book' has 'Pages'
-
Question 9 of 200
9. Question
1 pointsA, B, C and D live on floors 3 to 6 of the same six storeyed building. A lives on
fourth floor. Only one person lives on the floor between A and B, C does not live on a floor above A's floor.Who lives on a floor immediately above B's floor?
Correct
Incorrect
- B - 6th floor
- D - 5th floor
- A - 4th floor
- C - 3rd floor
B lives on the top floor.
-
Question 10 of 200
10. Question
1 pointsA, B, C and D live on floors 3 to 6 of the same six storeyed building. A lives on
fourth floor. Only one person lives on the floor between A and B, C does not live on a floor above A's floor.Who lives on the 5th floor?
Correct
Incorrect
- B - 6th floor
- D - 5th floor
- A - 4th floor
- C - 3rd floor
D lives on the fifth floor.
-
Question 11 of 200
11. Question
1 pointsAmong P, Q, R, S and T each having different height , Q is shorter than only T and P is taller than only S. Who will be third when they are arranged in descending
order of their height?Correct
Incorrect
T>Q>R>P>S
Hence, R is third in height among them.
-
Question 12 of 200
12. Question
1 pointsGeeta is senior to Shilpa but not Deepa. Gayatri is junior to Deepa. No one is senior to Fatima. Who is the most junior?
Correct
Incorrect
Fatima > Deepa > Geeta > Shilpa and Deepa > Gayatri
Hence, we cannot determine the most junior among them.
-
Question 13 of 200
13. Question
1 pointsSuresh is five ranks below top student Samir in a class of forty students. What is Suresh's rank from the bottom in the class?
Correct
Incorrect
Suresh's rank from the top = 5th + 1 = 6th
Hence, Suresh's rank from the bottom in the class=40-6+1
=41 -6
=35th -
Question 14 of 200
14. Question
1 pointsStudy the information given below and answer these question.
(i) P, Q, R, S, T, U and V are sitting along a circle facing the centre.
(ii) P is between T and S.
(iii) U is between Q and V.
(iv) Q is 2nd to the right of T.Which of the following pairs has its first member sitting second to the right of the second member?
Correct
Incorrect

-
Question 15 of 200
15. Question
1 pointsStudy the information given below and answer these question.
(i) P, Q, R, S, T, U and V are sitting along a circle facing the centre.
(ii) P is between T and S.
(iii) U is between Q and V.
(iv) Q is 2nd to the right of T.Which of the following pairs has its 2nd member sitting to the immediate left of the first member?
Correct
Incorrect
-
Question 16 of 200
16. Question
1 pointsStudy the information given below and answer these question.
(i) P, Q, R, S, T, U and V are sitting along a circle facing the centre.
(ii) P is between T and S.
(iii) U is between Q and V.
(iv) Q is 2nd to the right of T.What is the position of R?
Correct
Incorrect
-
Question 17 of 200
17. Question
1 pointsStudy the information given below and answer these question.
(i) P, Q, R, S, T, U and V are sitting along a circle facing the centre.
(ii) P is between T and S.
(iii) U is between Q and V.
(iv) Q is 2nd to the right of T.V is...........?
Correct
Incorrect
-
Question 18 of 200
18. Question
1 pointsStudy the information given below and answer these question.
(i) P, Q, R, S, T, U and V are sitting along a circle facing the centre.
(ii) P is between T and S.
(iii) U is between Q and V.
(iv) Q is 2nd to the right of T.Which of the following is the correct statement?
Correct
Incorrect
-
Question 19 of 200
19. Question
1 pointsFour of the following five are alike in a certain way and so form a group. Which is the one that does not belong to the group?
Correct
Incorrect
Except 'Cloth', all others comes under the cloth.
-
Question 20 of 200
20. Question
1 pointsFour of the following five are alike in a certain way and so form a group. Which is the one that does not belong to the group?
Correct
Incorrect
Except 'Tree', all others are part of a tree.
-
Question 21 of 200
21. Question
1 pointsFour of the following five are alike in a certain way and so form a group. Which is the one that does not belong to the group?
Correct
Incorrect
Except 'Picture', all others are physical activity.
-
Question 22 of 200
22. Question
1 pointsFour of the following five are alike in a certain way and so form a group. Which is the one that does not belong to the group?
Correct
Incorrect
Except 'Mustard', all others are flowers.
-
Question 23 of 200
23. Question
1 pointsFour of the following five are alike in a certain way and so form a group. Which is the one that does not belong to the group?
Correct
Incorrect
Except 'Boat', all others are transport system on ground.
-
Question 24 of 200
24. Question
1 pointswhile he was returning (1)/ from the office (2)/ a man attacked on (3)/ him with a dagger.(4) No error( 5)
Correct
Incorrect
Delete on
-
Question 25 of 200
25. Question
1 pointsThe decline of her moral (1)/ was caused by a lot of (2) /factors that were once (3)/ fascinating to-her (4) No error (5)
Correct
Incorrect
Change 'decline of to 'decline in'.
-
Question 26 of 200
26. Question
1 pointsHe took me to a restaurant (1)/ and ordered for two cup (2)/ of cold coffee (3) which the waiter brought in an hours(4)/No error.
Correct
Incorrect
Delete'/or' after order.
-
Question 27 of 200
27. Question
1 pointsThere are some animals (1)/than can live (2) both in water and land (3)/ without any difficulty. (4)/ No Error (5)
Correct
Incorrect
Place on before 'land'.
-
Question 28 of 200
28. Question
1 pointsTom and Dick start moving in opposite directions from a point. They both move 10.4 km. Dick moves to his left after the covers 6 km. Tom moves left and covers 6 km. Again Dick moves right and covers 10.4 km. Tom moves left and covers 31.2 km. How far are they both from each other?
Correct
Incorrect
-
Question 29 of 200
29. Question
1 pointsA river flows West to East and on the way turns left and goes in a semicircle round a hillock, and then turns left in a right angles. In which & reaction is the river finally flowing?
Correct
Incorrect
-
Question 30 of 200
30. Question
1 pointsStarting from a point'H'. Rita walked 36 m towards North. She turned to his right and walked 50 m. She then turned to his right and walked 36 m. She again turned to his right and walked 70 m and reached a point 'K' How far Rita is from the point'H' and in which direction?
Correct
Incorrect
-
Question 31 of 200
31. Question
1 pointsJatin who is facing North turns to his right and walks 30 m. Then he turns to his right and walks 14 m, then facing East he walks 30 m. How far is he from his original position?
Correct
Incorrect
-
Question 32 of 200
32. Question
1 pointsPointing to a man in a photograph, a woman said, "His brother's father is the only son of my grandfather." How is the woman related to the man in the photograph?
Correct
Incorrect
Only son of woman’s grandfather – Woman’s father;
Man’s brother father – Man’s father.
So, the woman is man’s sister. -
Question 33 of 200
33. Question
1 pointsPointing to a man, a woman said, “his mother is the only daughter of my mother" How is the woman related to the man.
Correct
Incorrect
Only daughtr of my mother - Myself. So, the woman is man’s mother.
-
Question 34 of 200
34. Question
1 pointsIf A is the brother of B; B is the sister of C; and C is the father of D, how D is related to A?
Correct
Incorrect
If D is Male, the answer is Nephew.
If D is Female, the answer is Niece.
As the sex of D is not known, hence, the relation between D and A cannot be determined.
Note: Niece - A daughter of one's brother or sister, or of one's brother-in-law or sister-in-law. Nephew - A son of one's brother or sister, or of one's brother-in-law or sister-in-law.
-
Question 35 of 200
35. Question
1 pointsA told B,"The girl I met yesterday was the youngest daughter of the brother–in–law of my friend’s mother." How is the girl related to A's friend?
Correct
Incorrect
Daughter of brother–in–law –-> Niece;
Mother’s niece –-> Cousin.
So, the girl is the cousin of A's friend. -
Question 36 of 200
36. Question
1 pointsPointing to a girl in the photograph, Amar said, “Her mother’s brother is the only son of my mother’s father.” How is the girl’s mother related to Amar ?
Correct
Incorrect
Only son of Amar’s mother’s father - Amar’s maternal uncle. So, the girl’s maternal uncle is Amar’s maternal uncle. Thus, the girl’s mother is Amar’s aunt.
-
Question 37 of 200
37. Question
1 points Correct
Correct
Incorrect
-
Question 38 of 200
38. Question
1 points Correct
Correct
Incorrect
-
Question 39 of 200
39. Question
1 points Correct
Correct
Incorrect
-
Question 40 of 200
40. Question
1 points Correct
Correct
Incorrect
-
Question 41 of 200
41. Question
1 pointsA series is established if one of the Five Answer Figures is placed at the "question-marked space". Question Figures form a series if they change from left to right according to some rule. The number of the Answer Figure which should be placed in the question-marked space is the answer. All the five figures i.e, four Problem Figures and one Answer Figure placed in the question-marked space should be considered as following the series.
Study the following question. Correct
Correct
Incorrect
-
Question 42 of 200
42. Question
1 points Correct
Correct
Incorrect
-
Question 43 of 200
43. Question
1 points Correct
Correct
Incorrect
-
Question 44 of 200
44. Question
1 points Correct
Correct
Incorrect
-
Question 45 of 200
45. Question
1 points Correct
Correct
Incorrect
-
Question 46 of 200
46. Question
1 pointsIf DELHI is coded as 73541 and CALCUTTA as 82589662, how can CALICUT be coded? (Assistant Grade, 1995)
Correct
The alphabets are coded as follows :
D E L H I C A U T
7 3 5 4 1 8 2 9 6
So, in CALICUT, C is coded as 8, A as 2, L as 5,I as 1, U as 9 and T as 6. Thus,
the code for CALICUT is 8251896.
Incorrect
The alphabets are coded as follows :
D E L H I C A U T
7 3 5 4 1 8 2 9 6
So, in CALICUT, C is coded as 8, A as 2, L as 5,I as 1, U as 9 and T as 6. Thus,
the code for CALICUT is 8251896.
-
Question 47 of 200
47. Question
1 pointsIn a certain code, RIPPLE is written as 613382 and LIFE is written as 8192.How is PILLER written in that code? (Railways, 1998)
Correct
The alphabets are coded as shown:
R I P L E F
6 1 3 8 2 9
So, in PILLER, P is coded as 3, I as 1, L as 8, E as 2 and R as 6. Thus, the code for PILLER is 318826.
Incorrect
The alphabets are coded as shown:
R I P L E F
6 1 3 8 2 9
So, in PILLER, P is coded as 3, I as 1, L as 8, E as 2 and R as 6. Thus, the code for PILLER is 318826.
-
Question 48 of 200
48. Question
1 pointsIn a certain code language 24685 is written as 33776.how is 35791 written in that code?(P.O. EXAM,1989)
Correct
(CLERLY ,in the code letters at odd places are one place ahead and those at even piaces are one place before the corresponding letter in the word.
Incorrect
(CLERLY ,in the code letters at odd places are one place ahead and those at even piaces are one place before the corresponding letter in the word.
-
Question 49 of 200
49. Question
1 pointsIn a certain code language 35796 is written as 44887.how is 46823 written in that code? (P.O.EXAM 1991)
Correct
the same pattern as in above question is followed i.e. 4 will be written as 5,6as 5,8as 9,2 as 1 and 3 as 4.so,the code becomes 55914.
Incorrect
the same pattern as in above question is followed i.e. 4 will be written as 5,6as 5,8as 9,2 as 1 and 3 as 4.so,the code becomes 55914.
-
Question 50 of 200
50. Question
1 pointsIf PALAM could be given the code number 43, what code number can be given to SANTACRUZ ? (Assistant Grade, 1995).
Correct
In the given code, A=1, B=2, C=3,...............,Z = 26 So, PALAM=16+1+12+1+13=43 Similarly, SANTACRUZ=19+1+14+20+1+3+18+21+26=123.
Incorrect
In the given code, A=1, B=2, C=3,...............,Z = 26 So, PALAM=16+1+12+1+13=43 Similarly, SANTACRUZ=19+1+14+20+1+3+18+21+26=123.
-
Question 51 of 200
51. Question
1 pointsPrime Minister Narendra Modi visited Thimphu on a two-day goodwill visit to Bhutan making it his first foreign visit, recently. Who among the following is the Prime Minister of Bhutan as of now?
Correct
Incorrect
-
Question 52 of 200
52. Question
1 pointsAccording to the ‘ICICI Lombard Tobacco Consumption Habits 2014’ survey, which of the following cities recorded highest cigarette consumption rate in the country?
Correct
Incorrect
-
Question 53 of 200
53. Question
1 pointsResearchers have found the Earth’s largest water reservoir around 643 km underneath mantle rock in
Correct
Incorrect
-
Question 54 of 200
54. Question
1 pointsThe govt plans to plant around what number of trees along the entire 1 lakh km National Highways network across the country to employ jobless youth and to protect environment?
Correct
Incorrect
-
Question 55 of 200
55. Question
1 pointsThe biggest of its kind ever held, the ‘Global Summit to End Sexual Violence in Conflict’ was held in which of the following cities, recently?
Correct
Incorrect
-
Question 56 of 200
56. Question
1 pointsWhich of the following actors has been appointed as UNICEF’s ‘celebrity advocate for child rights,’ recently?
Correct
Incorrect
-
Question 57 of 200
57. Question
1 pointsIndia beat South Korea 3-0 in its finishing match in the recently concluded men’s Hockey World Cup. India finished at which of the following positions?
Correct
Incorrect
-
Question 58 of 200
58. Question
1 pointsAs revealed by the UN agency, the Food and Agriculture Organisation (FAO), malnutrition is responsible for about ________ million deaths of children under the age of five every year.
Correct
Incorrect
-
Question 59 of 200
59. Question
1 pointsThe Prime Minister Narendra Modi described the bilateral relations between India and which of the following countries as ‘B2B’ relations. The first ‘B’ stands for Bharat in the term B2B.
Correct
Incorrect
-
Question 60 of 200
60. Question
1 pointsMandovi river water has been declared unsafe for swimming and fishing due to presence of high level of coliform bacteria in it. This river is situated in which of the following states?
Correct
Incorrect
-
Question 61 of 200
61. Question
1 pointsChina has signed business deals worth about USD 5 bn during Chinese Premier Li Keqiang’s recent visit to the country? Deals signed covers areas including exports and ship building.
Correct
Incorrect
-
Question 62 of 200
62. Question
1 pointsThe Andean Road System built by the Inca Empire has been granted World Heritage status recently. Which of the following agencies of the United Nations grant World Heritage status to cultural and natural sites in the world?
Correct
Incorrect
-
Question 63 of 200
63. Question
1 pointsChina has signed business deals worth about USD 5 bn during Chinese Premier Li Keqiang’s recent visit to the country? Deals signed covers areas including exports and ship building.
Correct
Incorrect
-
Question 64 of 200
64. Question
1 pointsName the Brazilian President who has been officially endorsed by the governing Workers Party, recently, to run for reelection to be held in Oct?
Correct
Incorrect
-
Question 65 of 200
65. Question
1 pointsKiren Rijiju led the Indian delegation to 6th Asian Ministerial Conference on Disaster Reduction held in Bangkok recently. He is the Minister of State for ________at present.
Correct
Incorrect
-
Question 66 of 200
66. Question
1 pointsWhich of the following sites in India has got World Heritage site tag recently?
Correct
Incorrect
-
Question 67 of 200
67. Question
1 pointsAccording to a UNICEF report, at present only ________of rural Indian population has access to good toilet and sanitation facilities.
Correct
Incorrect
-
Question 68 of 200
68. Question
1 pointsIndia has ratified an Additional Protocol with the International Atomic Energy Agency (IAEA) recently. What will be its impact on India’s civil nuclear programme?
Correct
Incorrect
-
Question 69 of 200
69. Question
1 pointsPopular film director-producer Ramanarayanan passed away recently. He was associated with ________films.
Correct
Incorrect
-
Question 70 of 200
70. Question
1 pointsThe govt has decided to raise the import duty on sugar from 15 per cent to what per cent recently?
Correct
Incorrect
-
Question 71 of 200
71. Question
1 pointsHindustan Zinc has inked a pact with which of the following state govts to build 30,000 toilets rural toilets for families below poverty line under ‘Nirmal Bharat Abhiyan’?
Correct
Incorrect
-
Question 72 of 200
72. Question
1 pointsThe World Bank has lowered India’s GDP growth forecast for 2014-15 to what per cent? Earlier it has forecasted of 5.7 per cent GDP growth.
Correct
Incorrect
-
Question 73 of 200
73. Question
1 pointsIn her first stand-alone visit abroad as the External Affairs Minister, Sushma Swaraj is scheduled to visit which of the following countries on June 25-27?
Correct
Incorrect
-
Question 74 of 200
74. Question
1 pointsAs per the latest data released by Swiss National Bank (SNB), Switzerland’s central banking authority, Indian money in Swiss banks has risen to over
Correct
Incorrect
-
Question 75 of 200
75. Question
1 pointsWho among the following has been chosen for the prestigious Jnanpith award for 2013? He will be the recipient of the 49th Jnanpith award.
Correct
Incorrect
-
Question 76 of 200
76. Question
1 pointsWhich of the following pairs won the women’s doubles title at the Tri-Nation squash doubles tournament in Kuala Lumpur, Malaysia recently?
Correct
Incorrect
-
Question 77 of 200
77. Question
1 pointsThe central govt announced to launch a campaign to ensure 100 per cent immunization of children in states hit by encephalitis outbreak. This deadly disease is transmitted by
Correct
Incorrect
-
Question 78 of 200
78. Question
1 pointsThe central govt announced to launch a campaign to ensure 100 per cent immunization of children in states hit by encephalitis outbreak. This deadly disease is transmitted by
Correct
Incorrect
-
Question 79 of 200
79. Question
1 pointsWe often read about Jaipur Foot in newspapers. What is Jaipur Foot?
Correct
Incorrect
-
Question 80 of 200
80. Question
1 pointsWho among the following has topped the Indian Institutes of Technology-Joint Entrance Examination (IIT-JEE) Advanced
2014?Correct
Incorrect
-
Question 81 of 200
81. Question
1 pointsWhich of the following industrial groups in India has announced to invest Rs 1.8 lakh cr ($30 bn) across businesses over the next three years to break into the Fortune 50 club?
Correct
Incorrect
-
Question 82 of 200
82. Question
1 pointsName the defending champion of the FIFA World Cup which made a shock early exit from the 2014 World Cup after a disappointing 0-2 loss against Chile?
Correct
Incorrect
-
Question 83 of 200
83. Question
1 pointsThe NDA govt has decided to bring broad changes in MNREGA scheme. Which of the following are the changes proposed?
Correct
Incorrect
-
Question 84 of 200
84. Question
1 pointsSri Lankan parliament has overwhelmingly voted not to allow which of the following recently?
Correct
Incorrect
-
Question 85 of 200
85. Question
1 pointsWhat is India’s ranking in the latest annual ranking of the Global Peace Index?
Correct
Incorrect
-
Question 86 of 200
86. Question
1 pointsShekhar Dutt resigned as the governor of which of the following states recently?
Correct
Incorrect
-
Question 87 of 200
87. Question
1 pointsAccording to a paper published recently in the journal Climate Dynamics, the Indus basin is projected to warm with average temperatures set to increase by around ________by 2080.
Correct
Incorrect
-
Question 88 of 200
88. Question
1 pointsWhich of the following leading online retailers has entered smartphone war with launch of 3D phone ‘Fire’ recently?
Correct
Incorrect
-
Question 89 of 200
89. Question
1 pointsWho among the following bagged the FIDE World Rapid Chess Championship title in Dubai recently?
Correct
Incorrect
-
Question 90 of 200
90. Question
1 pointsWhich of the following plants has become the single largest power generating unit in the country?
Correct
Incorrect
-
Question 91 of 200
91. Question
1 pointsThe capital markets regulator SEBI cleared a slew of reforms recently. Which of the following NOT among the reforms cleared?
Correct
Incorrect
-
Question 92 of 200
92. Question
1 pointsFelipe VI took oath as the new king of which of the following countries, recently?
Correct
Incorrect
-
Question 93 of 200
93. Question
1 pointsName the plant scientist who has won the USD 250,000 World Food Prize for his contribution in increasing global wheat production by more than 200 mn tonnes in the years following the Green Revolution?
Correct
Incorrect
-
Question 94 of 200
94. Question
1 pointsThe state govt of which of the following states has passed a law to ban dance bars across the state, recently?
Correct
Incorrect
-
Question 95 of 200
95. Question
1 points204. India finished 6th in overall medals tally with 2 gold, 5 silver, 5 bronze in the Asian Junior Athletics Championships held in Chinese Taipei recently. Which of the following countries finished on top?
Correct
Incorrect
-
Question 96 of 200
96. Question
1 pointsThe public sector thermal and hydro power generation company NTPC has sought lifting of embargo on Lata Tapovan project work. The project was to come up in which of the following states?
Correct
Incorrect
-
Question 97 of 200
97. Question
1 pointsJuan Manuel Santos has been elected to a second term as President in which of the following countries, recently?
Correct
Incorrect
-
Question 98 of 200
98. Question
1 pointsThe Bangalore-based GMR Infrastructure has won the arbitration proceedings initiated against the Govt of which of the following countries after the latter unilaterally cancelled the $500-mn contract given to GMR?
Correct
Incorrect
-
Question 99 of 200
99. Question
1 pointsWhich of the following leading Indian software exporters has become the world’s third largest employer of people in the IT sector, with over 3 lakh employees? At the present pace it is all set to become the second largest employer in IT sector this year.
Correct
Incorrect
-
Question 100 of 200
100. Question
1 pointsA panel headed by Parthasarathi Shome submitted its recommendations, recently. Which of the following is NOT correct with respect to these recommendations?
Correct
Incorrect
-
Question 101 of 200
101. Question
1 pointsThe head of a rivet is made by
Correct
Incorrect
-
Question 102 of 200
102. Question
1 pointsThe Poisson’s Ratio for concrete is approximately
Correct
Incorrect
-
Question 103 of 200
103. Question
1 pointsThe resistance offered to slipping of steel bars in concrete is due to
Correct
Incorrect
-
Question 104 of 200
104. Question
1 pointsA queen closer may be placed in
Correct
Incorrect
-
Question 105 of 200
105. Question
1 pointsThe condensation of moisture trapped in air takes place at
Correct
Incorrect
-
Question 106 of 200
106. Question
1 pointsThe bond strength of concrete increases with
Correct
Incorrect
-
Question 107 of 200
107. Question
1 pointsFor M150 grade cement, if the average bond stress is kg/cm2 then as per IS : 456, the length of embedment of bar of diameter ‘d’ should be
Correct
Incorrect
-
Question 108 of 200
108. Question
1 pointsThe process of filling up all nail holes, cracks etc. with putty is known as
Correct
Incorrect
-
Question 109 of 200
109. Question
1 pointsH piles
Correct
Incorrect
-
Question 110 of 200
110. Question
1 pointsA body falling from a vertical height of 10m pierced through a distance of lm in sand. It faced an average retardation in sand amounting
Correct

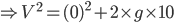

$(0)^{2}=(20g)+2a\times 1
 Incorrect
Incorrect
$(0)^{2}=(20g)+2a\times 1" />
$(0)^{2}=(20g)+2a\times 1
or = -10g
-
Question 111 of 200
111. Question
1 pointsIf a stone is dropped from the window of a moving train, it will hit the ground following a
Correct
x = vt
or t = x/v

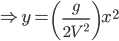
or y =
 equation of a parabola.Incorrect
equation of a parabola.Incorrect
x = vt
or t = x/v
or y =
equation of a parabola. -
Question 112 of 200
112. Question
1 pointsTwo bodies of masses m1 and m2 are dropped from heights h1 and h2 respectively. They reach the ground after time t1 and t2 respectively. Which of the following relations is correct?
Correct
 and
and 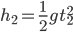
 Incorrect
Incorrect
and -
Question 113 of 200
113. Question
1 pointsA stone is thrown upward from the surface of earth with an initial speed of 5 m/sec. The stone comes to rest at a height of
Correct
u = 5m/s , v = 0
Now ,
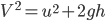

 h =
h = 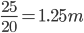 Incorrect
Incorrect
u = 5m/s , v = 0
Now ,
h = -
Question 114 of 200
114. Question
1 pointsThe moon’s radius is one-fourth of that of the earth and its mass is 1/80 time that of the earth. If g represents the acceleration due to gravity on the surface of the earth, that on the surface of the moon is
Correct
Incorrect
-
Question 115 of 200
115. Question
1 pointsDirections (115-118): The following questions are based on the information given below. Read it carefully and answer the questions.
Water at 20°C flows between two large parallel plates at a distance of 1.6 mm apart. Its average velocity is 0.15 m/sec.What is the maximum velocity?
Correct
The maximum velocity is given by
 = 0.225 m/secIncorrect
= 0.225 m/secIncorrect
The maximum velocity is given by
= 0.225 m/sec -
Question 116 of 200
116. Question
1 pointsWhat is the pressure drop?
Correct
The pressure drop
 = -808 N/mIncorrect
= -808 N/mIncorrect
-
Question 117 of 200
117. Question
1 pointsWhat is the wall shearing stress?
Correct
The wall sharing stress
 Incorrect
Incorrect
The wall sharing stress
-
Question 118 of 200
118. Question
1 pointsWhat is the co-efficient of friction?
Correct
Coefficient of friction
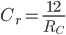

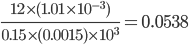 Incorrect
Incorrect
Coefficient of friction
-
Question 119 of 200
119. Question
1 pointsThe best unit duration of storm for a unit hydrograph is equal to
Correct
Incorrect
-
Question 120 of 200
120. Question
1 pointsAccording to Dicken’s formula for estimating floods, the peak discharge is proportional to
Correct
Incorrect
-
Question 121 of 200
121. Question
1 pointsSleeper density in India is normally kept as (where M is the rail length in metres)
Correct
Incorrect
-
Question 122 of 200
122. Question
1 pointsStandard size of wooden sleeper for Broad Gauge track is
Correct
Incorrect
-
Question 123 of 200
123. Question
1 pointsIf ‘d’ is the depth of aquifer through which water is flowing, then the relationship between permeability K and transmissibility T is given by
Correct
Incorrect
-
Question 124 of 200
124. Question
1 pointsSwitch angle is the angle between
Correct
Incorrect
-
Question 125 of 200
125. Question
1 pointsMaximum value of throw of switch for Broad Gauge track is
Correct
Incorrect
-
Question 126 of 200
126. Question
1 pointsIf a is the angle of crossing, then the number of crossing ‘N’ according to right angle method is given by
Correct
Incorrect
-
Question 127 of 200
127. Question
1 pointsAs compared to shallow wells, deep wells have
Correct
Incorrect
-
Question 128 of 200
128. Question
1 pointsIn case of stairs, Rise X tread should be between
Correct
Incorrect
-
Question 129 of 200
129. Question
1 pointsAfter prestressing process is complete, any loss of stress may be due to
Correct
Incorrect
-
Question 130 of 200
130. Question
1 pointsWhenever a number of columns are to be constructed in a row, which of the following will be preferred?
Correct
Incorrect
-
Question 131 of 200
131. Question
1 pointsIn kingpost truss, there will be
Correct
Incorrect
-
Question 132 of 200
132. Question
1 pointsAs the moisture from freshly queried limestone evaporates
Correct
Incorrect
-
Question 133 of 200
133. Question
1 pointsDuring storage, an explosive should be protected from
Correct
Incorrect
-
Question 134 of 200
134. Question
1 pointsA shoe of cast iron or mild steel on pile is not necessary in case the pile is driven through
Correct
Incorrect
-
Question 135 of 200
135. Question
1 pointsThe lower half of the arch between the crown and a skew back is known as
Correct
Incorrect
-
Question 136 of 200
136. Question
1 pointsA depression cut in the frame to receive the door is known as
Correct
Incorrect
-
Question 137 of 200
137. Question
1 pointsA wooden block hinged on the post outside the door is known as
Correct
Incorrect
-
Question 138 of 200
138. Question
1 pointsRCC electric poles are generally made of
Correct
Incorrect
-
Question 139 of 200
139. Question
1 pointsThe joints provided in wooden floors are of
Correct
Incorrect
-
Question 140 of 200
140. Question
1 pointsWhich of the following screws has square head?
Correct
Incorrect
-
Question 141 of 200
141. Question
1 pointsThe points of low sound intensity causing unsatisfactory bearing are called
Correct
Incorrect
-
Question 142 of 200
142. Question
1 pointsFor maximum day light, the window in a room should be located on
Correct
Incorrect
-
Question 143 of 200
143. Question
1 pointsThe total energy of particle executing simple harmonic motion is proportional to
Correct
Incorrect
-
Question 144 of 200
144. Question
1 pointsDead slow is a
Correct
Incorrect
-
Question 145 of 200
145. Question
1 pointsThe bars in cement concrete pavement are at:
Correct
Incorrect
-
Question 146 of 200
146. Question
1 pointsThe function of an expansion joint in rigid pavements is to
Correct
Incorrect
-
Question 147 of 200
147. Question
1 pointsThe most suitable equipment for compacting clayey soils is a
Correct
Incorrect
-
Question 148 of 200
148. Question
1 pointsThe cambers of shoulders in water bound macaham roads is
Correct
Incorrect
-
Question 149 of 200
149. Question
1 pointsA truss element
Correct
Incorrect
-
Question 150 of 200
150. Question
1 pointsWhich of the following could be the unit of rotational inertia of a body in cgs system?
Correct
Incorrect
-
Question 151 of 200
151. Question
1 pointsA warped wall used in Sarda type fall has
Correct
Incorrect
-
Question 152 of 200
152. Question
1 pointsIn glacis type falls, the upstream glacis has the slopes (horizontal to vertical)
Correct
Incorrect
-
Question 153 of 200
153. Question
1 pointsIn montague type falls,
Correct
Incorrect
-
Question 154 of 200
154. Question
1 pointsThe discharge through a cross-regulator is determined by using
Correct
Incorrect
-
Question 155 of 200
155. Question
1 pointsIn the design of launching aprons used for diversion head works, it is usually assumed that the aprons will ultimately launch to a slope (horizontal to vertical) of
Correct
Incorrect
-
Question 156 of 200
156. Question
1 pointsAccording to Khosla’s theory, the exit gradient
Correct
Incorrect
-
Question 157 of 200
157. Question
1 pointsRetrogression of the bed level of river on the d/s of a weir occurs because
Correct
Incorrect
-
Question 158 of 200
158. Question
1 pointsThe equation for channel flow V = 0.66 m D0.64 was developed by
Correct
Incorrect
-
Question 159 of 200
159. Question
1 pointsThe discharge through θ, 90° notch is proportional to
Correct
Incorrect
-
Question 160 of 200
160. Question
1 pointsThe modulus of elasticity (E) of concrete is given by
Correct
Incorrect
-
Question 161 of 200
161. Question
1 pointsThe average life of concrete roads is taken as
Correct
Incorrect
-
Question 162 of 200
162. Question
1 pointsDuring Testing machine is used for conducting
Correct
Incorrect
-
Question 163 of 200
163. Question
1 pointsThe shape of the curve showing variation of shear stress over the rectangular cross-section of a beam is
Correct
Incorrect
-
Question 164 of 200
164. Question
1 pointsThe moment of inertia of a thin spherical shell about its diameter is
Correct
Incorrect
-
Question 165 of 200
165. Question
1 pointsIf the magnitude of the resultant of two forces A and 2A acting at a point P is 50 N and the included angle is 90°, then
Correct
Incorrect
-
Question 166 of 200
166. Question
1 pointsRivets are generally specified by
Correct
Incorrect
-
Question 167 of 200
167. Question
1 pointsLoess is
Correct
Incorrect
-
Question 168 of 200
168. Question
1 pointsGun powder can be destroyed by
Correct
Incorrect
-
Question 169 of 200
169. Question
1 pointsWhich of the following tests is performed to know the resistance to flow of the given bituminous material?
Correct
Incorrect
-
Question 170 of 200
170. Question
1 pointsIn case of hilly roads, as per I.R.C. recommendations, the limiting gradient should not be more than
Correct
Incorrect
-
Question 171 of 200
171. Question
1 pointsThe permissible error in changing under average conditions is
Correct
Incorrect
-
Question 172 of 200
172. Question
1 pointsIn centesimal system the circumference is divided into
Correct
Incorrect
-
Question 173 of 200
173. Question
1 pointsWhich principle does not apply to a balloon lifting in air?
Correct
Incorrect
-
Question 174 of 200
174. Question
1 pointsThe dimensions of coefficient of dynamic friction are
Correct
Incorrect
-
Question 175 of 200
175. Question
1 pointsThe points on the celestial sphere directly above the observer’s station is called
Correct
Incorrect
-
Question 176 of 200
176. Question
1 pointsCoefficient of uniformity signifies the ratio
Correct
Incorrect
-
Question 177 of 200
177. Question
1 pointsWater flows upward and downward in
Correct
Incorrect
-
Question 178 of 200
178. Question
1 pointsThe optimum PH range for coagulation is
Correct
Incorrect
-
Question 179 of 200
179. Question
1 pointsA unit cell is defined by three translation vectors of lengths a, b and c and three angles a, P and y between the vectors. A hexagonal system is one when
-
Question 180 of 200
180. Question
1 pointsStandard B.O.D. is determined at
Correct
Incorrect
-
Question 181 of 200
181. Question
1 pointsThe moment of a couple is a
Correct
Incorrect
-
Question 182 of 200
182. Question
1 pointsThe critical depth of a channel is given by
-
Question 183 of 200
183. Question
1 pointsA hinged column carries critical load W. Now if one end is made fixed, the critical load will be
Correct
Incorrect
-
Question 184 of 200
184. Question
1 pointsThe thickness of continental crust ranges from
Correct
Incorrect
-
Question 185 of 200
185. Question
1 pointsWater containing dissolved carbon dioxide can dissolve
Correct
Incorrect
-
Question 186 of 200
186. Question
1 pointsA body of rock characterized by lithological homogeneity is called
Correct
Incorrect
-
Question 187 of 200
187. Question
1 pointsIn drinking water, the permissible limit is least for which of the following metals?
Correct
Incorrect
-
Question 188 of 200
188. Question
1 pointsAir relief values are provided
Correct
Incorrect
-
Question 189 of 200
189. Question
1 pointsAt Rihand dam project, water falls through a height of 210 metres. Assuming that whole of the energy due to fall is converted into heat, the rise in temperature of water would be (Given that J = 4.2 Joules per Cal, g = 9.8 m/s2)
Correct
Incorrect
-
Question 190 of 200
190. Question
1 pointsA series of straight parallel and equally spaced contours represents
Correct
Incorrect
-
Question 191 of 200
191. Question
1 pointsIn case, the length of a chain used for measurements is too short, the error will be
Correct
Incorrect
-
Question 192 of 200
192. Question
1 pointsThe best method of applying water to sandy undulating area is
Correct
Incorrect
-
Question 193 of 200
193. Question
1 pointsWhich of the following types of bricks are preferred for panel walls in multi-storeyed buildings?
Correct
Incorrect
-
Question 194 of 200
194. Question
1 pointsLime used for works under water is
Correct
Incorrect
-
Question 195 of 200
195. Question
1 pointsThe rate of hydration and hydrolysis of cement depends upon its
Correct
Incorrect
-
Question 196 of 200
196. Question
1 pointsIn asbestos cement sheets, the percentage of asbestos is nearly
Correct
Incorrect
-
Question 197 of 200
197. Question
1 pointsThe presence of whittish spots or streaks in timber wood is called
Correct
Incorrect
-
Question 198 of 200
198. Question
1 pointsA vehicle is traveling at 80 km per hr. Assuming that the driver’s perception time is 1.5 second and the reaction time is 0.5 second, what is the stopping distance on a dry level concrete pavement for which the coefficient of friction between the pavement and the Tyre is 0.35?
Correct
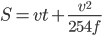
Here v = 80 km/hr
=

f = 0.35 : t = 1.5 + 0.5 = 2sec
putting all the figures in equation
(i) we get ,
s = 116.4m
Incorrect
Here v = 80 km/hr
=
f = 0.35 : t = 1.5 + 0.5 = 2sec
putting all the figures in equation
(i) we get ,
s = 116.4m
-
Question 199 of 200
199. Question
1 pointsIn the above question, what will be the stopping distance if the vehicle is traveling down a 3 per cent grade. Assume all other conditions are same as in question number 48.
Correct
Taking into accounting grade G .
We have
S =
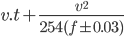
Positive sign (+) is for grade up and negative sign (-) is for grade down.
In the present case,
 = 121 m
= 121 m=> S = 121 m
Incorrect
Taking into accounting grade G .
We have
S =
Positive sign (+) is for grade up and negative sign (-) is for grade down.
In the present case,
= 121 m=> S = 121 m
-
Question 200 of 200
200. Question
1 pointsWhat is the total super elevation required for a road curve of 300 m radius for a vehicle speed of 80 kmph? The width of the road is 15m and the coefficient of friction is 0.15.
Correct
We have the relation for super elevation given by
e + f =
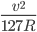
where, e = super elevation
f = coefficient of friction = 0.15
v = vehicle speed (80 kmph)
R = Radius of rod curve (300 m)
Thus e + f =


i.e 1 in 50
 Total super elevation =
Total super elevation = 
For bituminous surface, a maximum camber of 1 in 60 is required. Thus no super elevation is needed.
Incorrect
We have the relation for super elevation given by
e + f =
where, e = super elevation
f = coefficient of friction = 0.15
v = vehicle speed (80 kmph)
R = Radius of rod curve (300 m)
Thus e + f =
i.e 1 in 50
Total super elevation = For bituminous surface, a maximum camber of 1 in 60 is required. Thus no super elevation is needed.
its helpfull
nice mock test
Nice
gauravbagul87@gmail.com